RAG infrastructure should not be designed only around the LLM or the vector database. In a production system, the entire data path matters: where documents are stored, where embeddings are generated, where the vector index is located, where permissions are checked, how the API assembles context, and how close the reranker and LLM are to this path.
The main principle is to split RAG into two layers:
- Data ingestion layer: documents → object storage → parsing → chunks → embeddings → vector database. This layer can be optimized for cost, batch processing, and reindexing.
- User response layer: user → API → permission check → query embedding → vector search → metadata and chunks → reranker → LLM → response. This layer should be optimized for latency, security, and predictable p95.
Object storage is best used as the source of truth for original documents, versions, chunks, and processing artifacts. The vector database should be treated as a fast search layer, not as the only document store. The API or orchestrator should be located close to the index, metadata, cache, and model endpoints because it participates in every online request.
If documents are stored in one region, the index is in another, the embedding model is called through an external endpoint, and chunks are read from cold object storage on every request, RAG will be slow not because of a “bad model,” but because of the architecture. If permissions are checked after search or after context assembly, the issue is no longer only latency — it also becomes a data leakage risk.
A reliable RAG architecture starts with a simple question: which components participate in the online response and must be placed close together, and which belong to data preparation and can be scaled separately?
Why RAG Is Slow for Reasons Beyond the Model

RAG design often starts with choosing an LLM or a vector database. This is understandable: the model answers the user, and the vector database finds relevant fragments. But in a production environment, the bottleneck is often somewhere else.
The system may be slow or unreliable because of the architecture: documents are stored in one region, the index is located in another, the API calls an external embedding model, chunks are pulled from cold storage, and access rights are checked too late — after search or after context assembly.
RAG takes a user query, finds relevant fragments in corporate data, and passes them to the LLM as context. That means the infrastructure is responsible not only for search quality, but also for data placement, network proximity between components, access control, and predictable online request latency.
The key decisions come down to several questions:
- Where should object storage for original documents, versions, and chunks be located?
- Where should the vector database or vector index run?
- What role should the API, backend, and orchestrator play?
- How close should the embedding model, reranker, and LLM be to them?
- Where should metadata, access rights, and cache be stored?
- How should latency be measured, and how can prohibited documents be prevented from entering the model context?
To keep these decisions from turning into a set of disconnected settings, RAG should be split into two flows: data ingestion and preparation on one side, and user request serving on the other. Next, we will examine these two layers and show which components should be placed close together, and which can be scaled and optimized independently.
Two RAG Layers: Data Ingestion and Request Serving
As mentioned earlier, RAG is easier to reason about as two separate layers: the data ingestion layer and the user response layer. They have different requirements. The first can be optimized for cost, batch processing, and reindexing. The second should be optimized for latency, network proximity between components, and security.
Ingestion Layer: Preparing Documents for Search
The ingestion layer is responsible for turning corporate documents into a searchable index.
The basic chain looks like this: documents → object storage → parsing → chunks → embeddings → vector database.
A document first lands in object storage as the primary storage layer. This is where originals, versions, extracted text, processing artifacts, and indexing manifests are stored: which file was processed, with which model, when, and according to which rules.
After that, the document goes through parsing, chunking, embedding generation, and writing to the vector index. This layer does not have to be instant. It can run on events, on a schedule, or in batches, scale separately from the API, and move some compute work to cheaper resources.
A delay of several minutes is often acceptable if the system does not need to reflect document changes almost in real time. The main requirement is reproducibility: when the embedding model, chunk size, or cleanup rules change, the corpus can be reindexed from object storage instead of being reconstructed from an incomplete index.
Response Layer: Assembling Context Quickly and Safely
The response layer operates in the online path of a user request. Here, every extra delay is visible to the user, and every access-control mistake can lead to a data leak.

The basic chain is: user → API → permission check → query embedding → vector search → metadata and chunks → reranker → LLM → response.
The user query first reaches the API or orchestrator. This layer identifies the user, tenant, project, language, limits, and data policy. Then the query is converted into an embedding, sent to the vector database, searched with metadata and access filters applied, and only the permitted fragments are assembled into context for the LLM.
In this layer, components should be kept as close to one another as possible: the API, query embedding model, vector database, metadata, cache, reranker, and LLM. Every network hop adds latency, and cross-region calls quickly degrade p95.
It is especially important that permissions are applied before fragments enter the model context. If a prohibited document is first found and then passed to the API or LLM, with filtering applied only afterward, the leakage risk has already appeared.
Why These Layers Should Not Be Mixed
The ingestion layer can be placed and scaled more flexibly as long as its connection to object storage and the index is preserved. The response layer is better assembled inside one low-latency and secure perimeter.
This separation is what makes infrastructure decisions clearer: where to store documents, where to run the vector database, how close to place the API and models, and which tasks can run in the background without affecting the user response.
Where to Place the Main RAG Components
After splitting RAG into two layers, components become easier to place by role: what belongs to data preparation and what participates in the online user response.
The basic logic is this: heavy source files and batch processing should be kept closer to document storage, while everything involved in responding to the user should be placed closer to the API. This is especially important for query embeddings, the vector database, metadata, cache, reranker, and LLM: each of these components adds latency in the online path.
A practical placement map looks like this:
| Component | Where to Place It | Main Risk If Placed Incorrectly |
| Object storage | Close to the document corpus and ingestion layer | Large files will constantly move between regions |
| Parser and chunking | Close to object storage | Documents will have to be read over a slow or expensive network |
| Batch document embeddings | In the ingestion layer, close to storage | Large-scale chunk transfer becomes expensive and slow |
| Vector database / index | Close to the API, query embedding model, and metadata | Online search will degrade p95 |
| API / orchestrator | In the response layer, close to the index, cache, and models | One request turns into a chain of remote network calls |
| Query embedding | Close to the API and vector database | Every user request waits for an external model call |
| Reranker | Close to the API and index | An additional model call increases latency |
| LLM endpoint | Preferably in the same region or cloud perimeter | Context size, queueing, and external SLA become unstable factors |
| Metadata and cache | Close to the API and search layer | Access filters and hot fragment reads slow down the response |
This map does not replace architecture design for a specific cloud, but it shows the basic principle. Object storage is the durable source of data and versions. The vector database is the fast search layer. The API is the orchestrator of the online request. Models should be placed based on whether they are part of the critical response path.
Security should be considered separately. Access rights must be applied before context is sent to the model, the cache must account for the user and tenant, and external model calls must be allowed by the data transfer policy. Otherwise, the system may be fast but unsafe.
After the general placement map, it is worth looking separately at the vector database: it is the most visible RAG component, but it cannot be chosen in isolation from the API, metadata, permissions, and latency requirements.
Vector Database: Fast Search in the Response Layer

In RAG, the vector database is the online search layer. It receives the embedding of the user query, returns the top-k relevant fragments, applies metadata and permission filters, and sometimes combines semantic and text search.
That is why the vector index should usually be located close to the API, the query embedding model, and the metadata store. If every search call goes to another region or an external service, latency quickly starts to affect the p95 of the entire RAG request.
The right option depends not on which database is “smarter,” but on the scenario:
| Option | When It Fits | Main Trade-off |
| PostgreSQL with pgvector | Moderate data volume, and the product already uses PostgreSQL | Simple to operate, but search scaling depends on the primary database |
| OpenSearch / Elasticsearch approach | Enterprise search, filters, facets, hybrid search | Strong for text search, but requires tuning and operations |
| Managed vector DB | High QPS, strict SLA, separate vector search layer | Lower operational burden, but stronger service dependency |
| Vector over object storage | Large archive with rare access | Cheaper storage, but higher latency |
| Graph + vector | Relationships between entities matter: contract, counterparty, project, email | More context, but a more complex data model |
For online RAG with latency requirements, the index is best kept in the low-latency response layer. For archival search, storage costs can be reduced at the expense of higher latency. In any case, the vector database should not become the only document store.
The vector index is needed for fast search, not for storing the entire history of the corpus. Original files, versions, chunks, indexing manifests, and processing artifacts are better kept in a separate durable layer. This role is usually handled by object storage.
Object Storage: The Source of Truth for Documents and Chunks
If the vector database is a fast catalog for search, object storage is the primary storage layer from which the RAG corpus can be rebuilt. It should contain the original PDF, DOCX, and HTML files, document versions, extracted text, chunks, indexing manifests, processing logs, and parsing artifacts.
Object storage is usually placed close to the ingestion layer and the main document corpus. This makes it cheaper and faster to read large files during parsing, reindexing, and reprocessing. However, the region should not be chosen based only on speed: for legal, financial, and personal data, data residency requirements and the cloud perimeter also matter.
Chunk text can be stored in different layers:
- In the vector database — faster for responses, but more expensive and harder to update;
- In a metadata store close to the API — a compromise between speed and manageability;
- In object storage — cheaper, but every read adds latency to the online request;
- In cache — convenient for hot fragments, but requires correct invalidation by permissions, user, and document version.

A practical example: the team changes the embedding model or chunk size. If originals, versions, and manifests are preserved in object storage, reindexing becomes a normal batch operation. If the data exists only in the response index, the corpus has to be reconstructed from an incomplete and not always reproducible layer.
Object storage provides durability for the RAG corpus, but it does not solve access control by itself. The next layer is document security: permissions must be applied before search, before chunks are read, and before fragments are passed into the model context.
Document Security: Permissions Before Search and Before Model Context

In RAG, it is not enough to check whether the user is allowed to see the final answer. The check has to happen earlier: before candidates are returned from search, before chunks are read, and before context is assembled for the LLM.
If a prohibited fragment first reaches the API or the model context, and the application tries to hide it only after generation, the leakage risk has already appeared. That is why access control must be part of the data path, not a final check at the output.
A minimum security model for RAG should cover several layers:
- Tenant isolation — separate storage areas, collections, encryption keys, or strict tenant_id filters are needed for customers, departments, or projects;
- Filtering before search or inside search — the vector database must account for the user, groups, document classification, access expiration, project, and region;
- A unified permission model for documents and chunks — if the source document is closed, its chunks, embeddings, metadata, and cached answers must be closed as well;
- Encryption and keys — object storage, metadata, the vector database, and backups should be encrypted; for sensitive corpora, it is useful to separate keys by tenant or data class;
- Auditing — document uploads, reindexing, fragment transfer into model context, and external calls should be logged;
- Secure cache — the cache for fragments and answers must account for the user, tenant, permission version, and document version.
External model calls should be controlled separately. If the embedding model, reranker, or LLM is outside the main cloud perimeter, the policy must explicitly allow or prohibit the transfer of query text, chunks, metadata, and user attributes.
The practical principle is simple: the API receives the user context and passes it into search; search returns only permitted candidates; and context assembly works only with the already filtered set. After that, the API layer itself can be examined — it is the layer that connects the user, permissions, search, models, limits, and auditing in a single online request.
API and Orchestrator: The Center of the Online Request

The API layer in RAG is not just the entry point for HTTP requests. It is the orchestrator of the online request: it connects the user, identity system, search, models, limits, auditing, and context assembly.
The full response chain usually passes through the API: user authentication, tenant and data policy detection, query embedding model call, vector database search with access filters, metadata and chunk retrieval, optional reranking, context assembly, LLM call, post-processing, logging, and auditing.
The API is best placed in the same region — and preferably within the same private network perimeter — as the vector database, metadata store, cache, and model endpoints. The reason is simple: a single user request consists of several sequential calls. Even a small cross-region delay, repeated five to seven times, can noticeably degrade response time.
For a global application, teams usually choose one of two approaches. The first is a regional response layer: user requests go to the nearest region where the API, index, and model are available. This reduces latency, but makes it harder to synchronize indexes, metadata, and permissions. The second is a central data layer: everything is served from one region if data, licensing, or security requirements demand it. This makes control easier, but increases latency for remote users.
The API should not compensate for a weak security architecture. If prohibited fragments first reach the orchestrator and are then filtered in code, the risk has already appeared. A safer approach is to pass the permission context into the search layer and read only permitted chunks.
Models in RAG: Embeddings, Reranker, and LLM

RAG does not use just one model, but several model functions. Their placement depends on whether they belong to the ingestion layer or the response layer.
The document embedding model works in the batch layer. It processes a large volume of chunks during initial indexing and reindexing. It is better to place it close to object storage and parsing so that large amounts of text do not have to move between regions.
The embedding model for user queries is part of the online path. Every request waits for its result, so the endpoint should be close to the API and vector database. An external endpoint in another region may be acceptable for a prototype, but in production it often becomes a constant source of latency and a dependency on an external SLA.
The reranker improves retrieval quality, but adds another model call. It should be kept close to the API and index, and it should receive only fragments that the user is already allowed to access.
The LLM generates the final response. There are usually three placement options:

| Option | When It Fits | Main Trade-off |
| Managed model in the same cloud and region | Simple operations and low network latency are needed | Less control over the internal implementation of the service |
| Self-hosted model in Kubernetes or on dedicated GPUs | Control over data, versions, and cost at high load is needed | More complex operations, scaling, and monitoring |
| External model through a public API | Fast start or a broad choice of models is needed | Latency, data transfer, contractual restrictions, and audit must be evaluated separately |
For sensitive documents, teams more often choose a managed model inside the same cloud perimeter or self-host the model in a private network. For less sensitive scenarios, an external LLM may be acceptable, but only if the data policy allows user queries and retrieved fragments to be sent to an external service.
The main relationship is this: the query embedding model, vector database, reranker, and LLM should be close to the API because they participate in every online request. The batch embedding model for documents can scale separately, but it must remain connected to object storage, corpus versions, and indexing manifests.
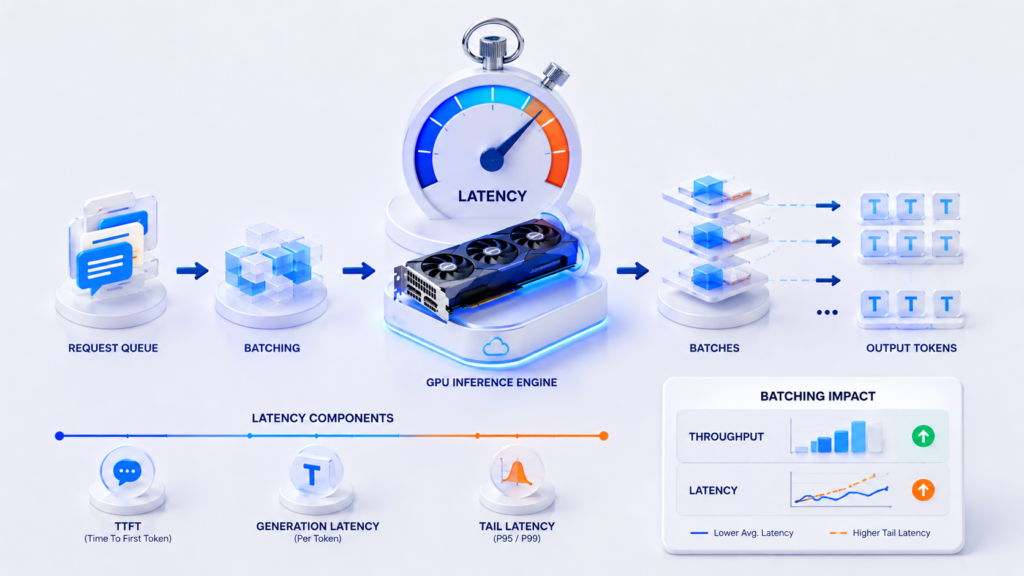
How to Estimate Latency Between Components
RAG request latency is not made up of a single LLM call. The online path includes a chain: user → API → permission check → query embedding → vector database → metadata and chunks → reranker → LLM → response to the user.
Each step adds its own time, and cross-region hops quickly degrade p95/p99. That is why it is important to measure not only average response time, but also tail latency: the slowest requests are often what define the user’s perception of service quality and SLA compliance.
A rough latency budget can be broken down as follows:
| Request Segment | With Close Placement | Risk with Remote Placement |
| User → API | 10–100 ms | A remote region adds tens or hundreds of milliseconds |
| API → IAM / permission check | 5–30 ms | An external identity system adds a network hop |
| API → query embedding | 20–200 ms | Another region or external endpoint worsens p95 |
| API → vector database | 10–80 ms | Cross-region search makes the response less stable |
| Vector DB → metadata / chunks | 5–50 ms when nearby; 30–200+ ms when reading from object storage | Cold or remote storage becomes part of the online path |
| API → reranker | 20–150 ms | An external model call adds latency and data transfer risk |
| API → LLM | 300–3000+ ms | Depends on context size, queue, model, and region |
| LLM → user | 10–100 ms | A remote endpoint worsens time to first token |
These numbers should be treated as an order of magnitude, not a universal standard. Real values depend on the cloud, region, request size, load, model, and caching strategy. For architecture design, the exact number in the table is less important than the total latency across the entire chain.
For example, if the target response must fit within 2 seconds at p95, and the LLM takes 1.2 seconds, around 800 ms remain for embedding, search, chunk retrieval, reranking, and network hops. In such an architecture, an external embedding endpoint in another region or reading every chunk from cold object storage will quickly consume the latency budget.
The main rule is this: the API, query embedding model, vector database, metadata, cache, reranker, and LLM should ideally be kept in one region and private network. Object storage with source documents can be optimized for cost and data residency requirements, but if chunks are read from it on every request, it effectively becomes part of the online path.
Conclusion
RAG should be designed not around a single vector database, but around the full data path. Object storage remains the source of truth for documents, versions, and reindexing. The vector database provides fast search, the API assembles the online request, and the query embedding model, reranker, and LLM should be placed as close to this layer as possible.
If components are spread across regions or clouds, this should be a deliberate trade-off: for data requirements, cost, availability, or model choice. For a production RAG system, it is important to define in advance where documents are stored, where search is performed, where permissions are checked, where models are called, and what latency budget is acceptable between these points.
FAQ
Does the entire RAG infrastructure need to be placed in one region?
Not necessarily. But the API, vector database, query embedding model, metadata, and LLM should preferably be kept as close as possible because they participate in every online request.
Where should the API or orchestrator be located?
In the response layer, close to the vector database, metadata, and model endpoints. This is the layer where authorization, search, context assembly, limits, and auditing come together.
Can documents be stored only in the vector database?
No. A vector database is suitable for search and embedding storage, but original files, versions, chunks, and processing artifacts are better stored in object storage.
When is PostgreSQL with pgvector enough?
When the data volume and load are moderate, and the product already uses PostgreSQL. As QPS and corpus size grow, a separate vector search layer may be needed.
How can documents be protected in multitenant RAG?
Filter search by tenant, user permissions, and document attributes before fragments enter the model context. Checking permissions only after the model response is not enough.
What contributes to RAG request latency?
API calls, permission checks, query embedding, vector search, metadata and chunk retrieval, optional reranking, LLM inference, and response delivery to the user.
Sources
1. Google Cloud Architecture Center — “RAG infrastructure for generative AI using Vertex AI and Vector Search”
2. Pinecone Docs — “Minimize latencies”
3. AWS Prescriptive Guidance — “Vector database comparison for RAG use cases”